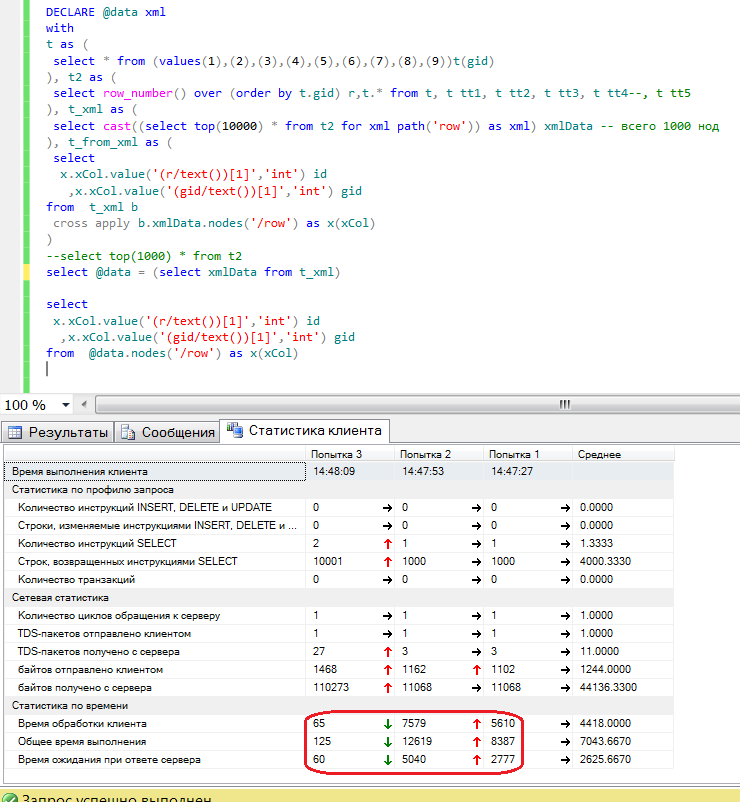
Пример, три варианта, в первых двух сгенерирована XML с 1000 узлов, в последнем 10000, первый и второй варианты отличаются представлением XML, значения в атрибутах или в тэгах. В третьем, главное отличие, XML сохраняется в переменную, и результат, производительность на несколько порядков выше.
Итог: 8 сек, 12 сек, и 125 мс, если хмл-ка маленькая 10-50 узлов можно и не использовать переменную, иначе придется, или использовать OpenXML.
Если запустить первый вариант с 10К, то будем ждать долго, минут 10 (не дождался прервал на 5), деградация в прогрессии.
with
t as (
select * from (values(1),(2),(3),(4),(5),(6),(7),(8),(9))t(gid)
), t2 as (
select row_number() over (order by t.gid) r,t.* from t, t tt1, t tt2, t tt3, t tt4--, t tt5
), t_xml as (
select cast((select top(1000) * from t2 for xml raw) as xml) xmlData -- всего 1000 нод
), t_from_xml as (
select
x.xCol.value('@r','int') id
,x.xCol.value('@gid','int') gid
from t_xml b
cross apply b.xmlData.nodes('/row') as x(xCol)
)
--select top(1000) * from t2
--select * from t_xml
select * from t_from_xml
with
t as (
select * from (values(1),(2),(3),(4),(5),(6),(7),(8),(9))t(gid)
), t2 as (
select row_number() over (order by t.gid) r,t.* from t, t tt1, t tt2, t tt3, t tt4--, t tt5
), t_xml as (
select cast((select top(1000) * from t2 for xml path('row')) as xml) xmlData -- всего 1000 нод
), t_from_xml as (
select
x.xCol.value('(r/text())[1]','int') id
,x.xCol.value('(gid/text())[1]','int') gid
from t_xml b
cross apply b.xmlData.nodes('/row') as x(xCol)
)
--select top(1000) * from t2
--select * from t_xml
select * from t_from_xml
DECLARE @data xml
with
t as (
select * from (values(1),(2),(3),(4),(5),(6),(7),(8),(9))t(gid)
), t2 as (
select row_number() over (order by t.gid) r,t.* from t, t tt1, t tt2, t tt3, t tt4--, t tt5
), t_xml as (
select cast((select top(10000) * from t2 for xml path('row')) as xml) xmlData -- всего 1000 нод
), t_from_xml as (
select
x.xCol.value('(r/text())[1]','int') id
,x.xCol.value('(gid/text())[1]','int') gid
from t_xml b
cross apply b.xmlData.nodes('/row') as x(xCol)
)
--select top(1000) * from t2
select @data = (select xmlData from t_xml)
select
x.xCol.value('(r/text())[1]','int') id
,x.xCol.value('(gid/text())[1]','int') gid
from @data.nodes('/row') as x(xCol)