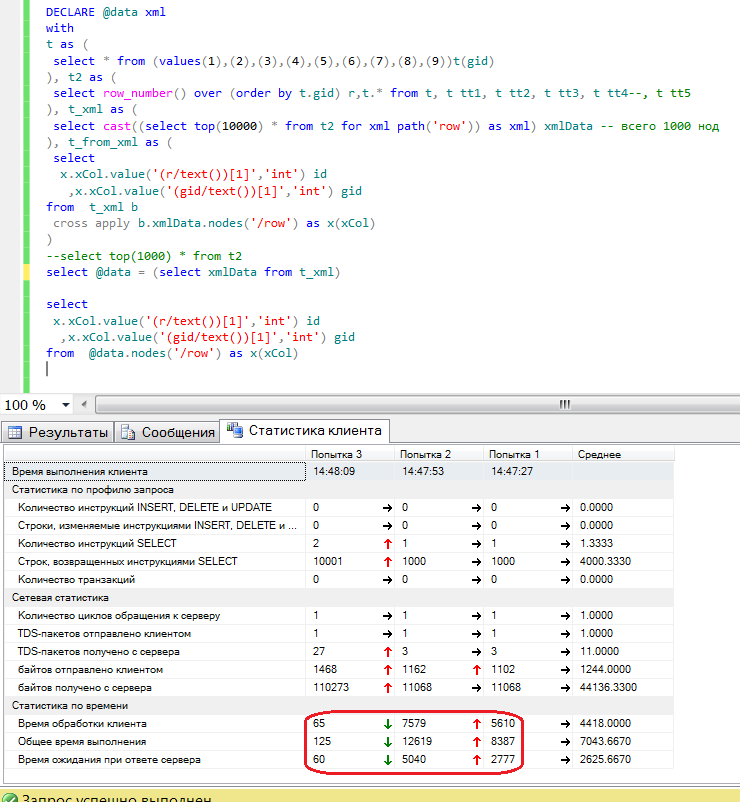
Воспользовавшись предложением offset fetch (аналог mysql-го limit-a) для пагинации, наткнулся на проблемку, при переходе между страницами запрос выдавал тот же результат.
В запросе всегда присутствует сортировка по одному из столбцов.
select rr.[rank] r, * v.*, otfile
, try_convert(date, col12, 104) col12D, convert(varchar(10), try_convert(date, col12, 104), 104) col12DH, ceiling((count(*) over())/10.0) pagesTotal from m_dev v
inner join (select * from (values('4370'),('4371'),('4372'),('4374'),('3461'),('3462'),('3464'),('3465'))t(code)) codes on (v.col10 like codes.code + '%')
inner join containstable (m_dev, col99, '("трансформатор" or "трансформатор*") and ("тока" or "тока*") and ("италия" or "италия*")', language 1049) rr on (v.id = rr.[key])
where v.deleted is null
order by r
offset 20 rows fetch next 10 rows only
Грешил на использование полнотекстового поиска, и объединение с результатами функции CONTAINSTABLE, провел эксперименты над данными попроще.
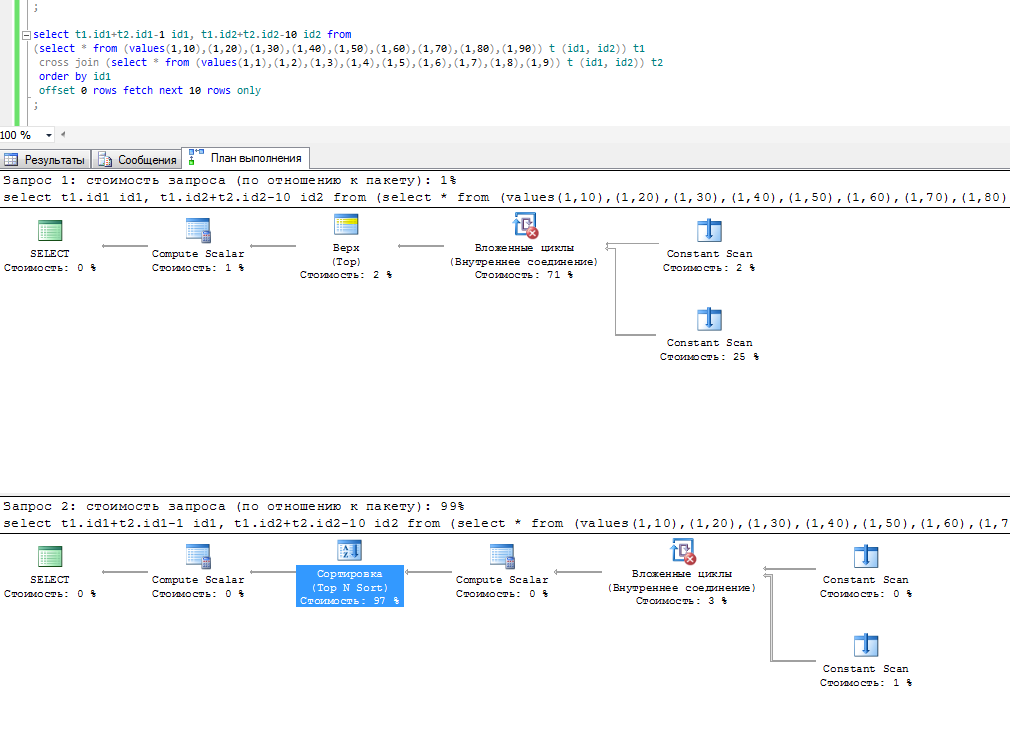
select t1.id1 id1, t1.id2+t2.id2-10 id2 from
(select * from (values(1,10),(1,20),(1,30),(1,40),(1,50),(1,60),(1,70),(1,80),(1,90)) t (id1, id2)) t1
cross join (select * from (values(1,1),(1,2),(1,3),(1,4),(1,5),(1,6),(1,7),(1,8),(1,9)) t (id1, id2)) t2
order by id1
offset 0 rows fetch next 10 rows only
;
select t1.id1 id1, t1.id2+t2.id2-10 id2 from
(select * from (values(1,10),(1,20),(1,30),(1,40),(1,50),(1,60),(1,70),(1,80),(1,90)) t (id1, id2)) t1
cross join (select * from (values(1,1),(1,2),(1,3),(1,4),(1,5),(1,6),(1,7),(1,8),(1,9)) t (id1, id2)) t2
order by id1
offset 10 rows fetch next 10 rows only
;
select t1.id1+t2.id1-1 id1, t1.id2+t2.id2-10 id2 from
(select * from (values(1,10),(1,20),(1,30),(1,40),(1,50),(1,60),(1,70),(1,80),(1,90)) t (id1, id2)) t1
cross join (select * from (values(1,1),(1,2),(1,3),(1,4),(1,5),(1,6),(1,7),(1,8),(1,9)) t (id1, id2)) t2
order by id1
offset 0 rows fetch next 10 rows only
;
select t1.id1+t2.id1-1 id1, t1.id2+t2.id2-10 id2 from
(select * from (values(1,10),(1,20),(1,30),(1,40),(1,50),(1,60),(1,70),(1,80),(1,90)) t (id1, id2)) t1
cross join (select * from (values(1,1),(1,2),(1,3),(1,4),(1,5),(1,6),(1,7),(1,8),(1,9)) t (id1, id2)) t2
order by id1
offset 10 rows fetch next 10 rows only
;
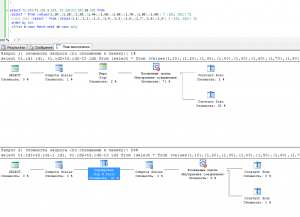
Получил результаты, соответственно для каждого запроса, появились косяки.
id1 id2 id1 id2 id1 id2 id1 id2
1 1 1 12 1 12 1 12
1 2 1 13 1 11 1 11
1 3 1 14 1 9 1 9
1 4 1 15 1 8 1 8
1 5 1 16 1 7 1 7
1 6 1 17 1 6 1 6
1 7 1 18 1 5 1 5
1 8 1 19 1 4 1 4
1 9 1 21 1 3 1 3
1 11 1 22 1 2 1 2
В плане выполнения появилась сортировка.
Итого, решаем проблему всегда добавляя последней сортировку по уникальному столбцу. Если его нет, генерим, как в примере. Если есть, как в моем рабочем запросе, в нем я просто добавил
order by r, v.id
select t1.id1+t2.id1-1 id1, t1.id2+t2.id2-10 id2, row_number() over (order by (select 1)) rn from
(select * from (values(1,10),(1,20),(1,30),(1,40),(1,50),(1,60),(1,70),(1,80),(1,90)) t (id1, id2)) t1
cross join (select * from (values(1,1),(1,2),(1,3),(1,4),(1,5),(1,6),(1,7),(1,8),(1,9)) t (id1, id2)) t2
order by id1, rn
offset 0 rows fetch next 10 rows only
;
select t1.id1+t2.id1-1 id1, t1.id2+t2.id2-10 id2, row_number() over (order by (select 1)) rn from
(select * from (values(1,10),(1,20),(1,30),(1,40),(1,50),(1,60),(1,70),(1,80),(1,90)) t (id1, id2)) t1
cross join (select * from (values(1,1),(1,2),(1,3),(1,4),(1,5),(1,6),(1,7),(1,8),(1,9)) t (id1, id2)) t2
order by id1, rn
offset 10 rows fetch next 10 rows only
;
id1 id2 rn id1 id2 rn
1 1 1 1 12 11
1 2 2 1 13 12
1 3 3 1 14 13
1 4 4 1 15 14
1 5 5 1 16 15
1 6 6 1 17 16
1 7 7 1 18 17
1 8 8 1 19 18
1 9 9 1 21 19
1 11 10 1 22 20
 Итого, решаем проблему всегда добавляя последней сортировку по уникальному столбцу. Если его нет, генерим, как в примере. Если есть, как в моем рабочем запросе, в нем я просто добавил
Итого, решаем проблему всегда добавляя последней сортировку по уникальному столбцу. Если его нет, генерим, как в примере. Если есть, как в моем рабочем запросе, в нем я просто добавил